📔【计算机网络】HTTP 协议知识点
- HTTP 请求方法
- HTTP 状态码
- Cookie 与 Session 的区别
- HTTP 的长连接与短连接
- HTTP/1.0、HTTP/1.1、HTTP/2.0 的变化
- HTTP 报文格式
- HTTP 分块传输编码
- 🗂 技术面试题汇总
- 参考资料
更多面试题总结请看:🗂【面试题】技术面试题汇总
本文记录一些在面试中遇到的关于 HTTP 协议的问题,系统学习推荐阅读《图解 HTTP》。
HTTP 请求方法
HTTP 请求方法表明了要对给定资源执行的操作,每一个请求方法都实现了不同的语义。包括:GET、HEAD、POST、PUT、PATCH、DELETE、OPTIONS,以及不常用的 CONNECT、TRACE。
- GET:获取服务器的指定资源
- HEAD:与 GET 方法一样,都是发出一个获取服务器指定资源的请求,但服务器只会返回 Header 而不会返回 Body。用于确认 URI 的有效性及资源更新的日期时间等。一个典型应用是下载文件时,先通过 HEAD 方法获取 Header,从中读取文件大小
Content-Length;然后再配合Range字段,分片下载服务器资源 - POST:提交资源到服务器 / 在服务器新建资源
- PUT:替换整个目标资源
- PATCH:替换目标资源的部分内容
- DELETE:删除指定的资源
- OPTIONS:用于描述目标资源的通信选项。可以用于检测服务器支持哪些 HTTP 方法,或者在 CORS 中发起一个预检请求,以检测实际请求是否可以被服务器所接受
- CONNECT:建立一个到由目标资源标识的服务器的隧道
- TRACE:执行一个消息环回测试,返回到服务端的路径。客户端请求连接到目标服务器时可能会通过代理中转,通过 TRACE 方法可以查询发送出去的请求的一系列操作(图示)
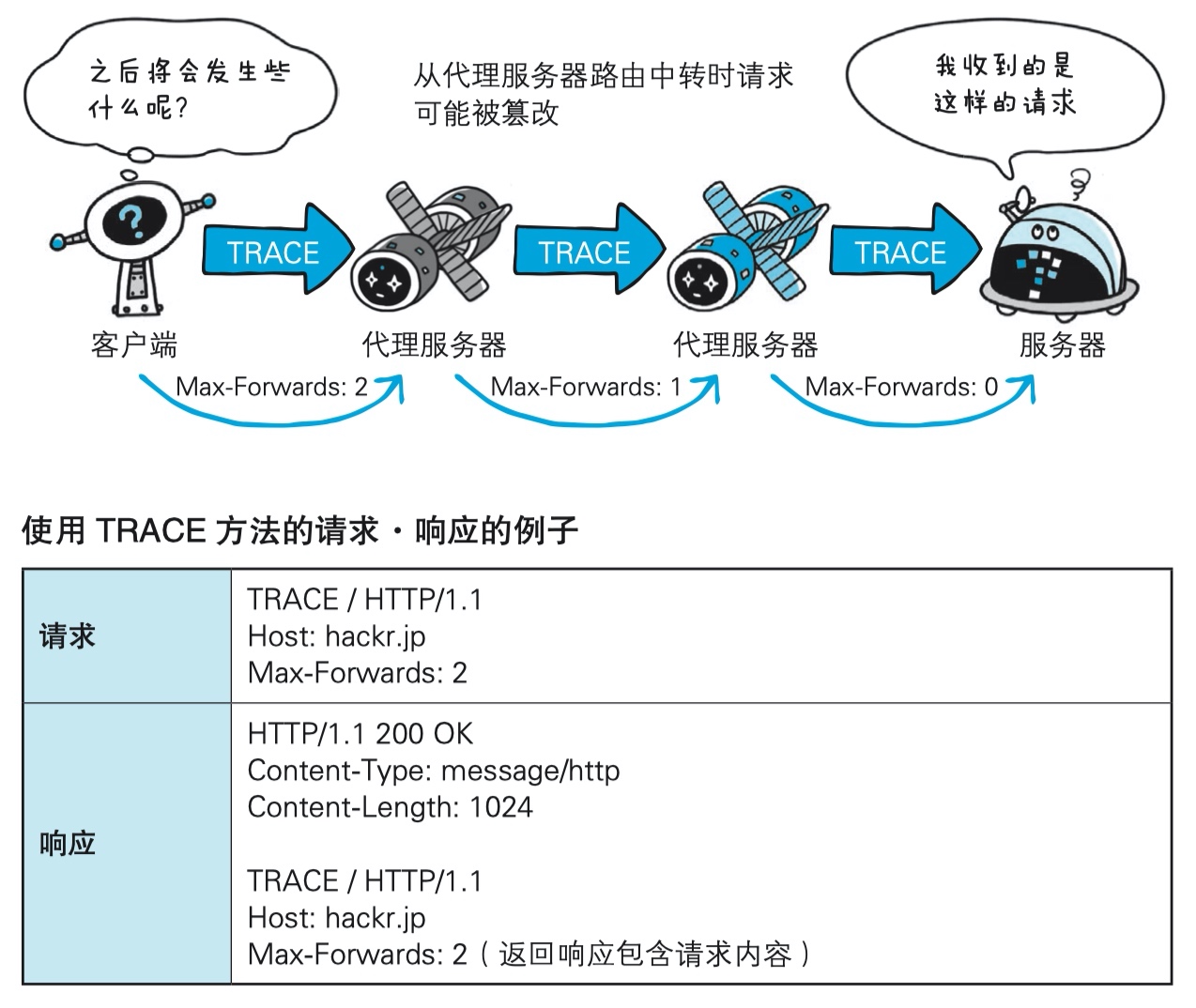{kind=link}
幂等的:一个 HTTP 方法是幂等的,指的是同样的请求执行一次与执行多次的效果是一样的。换句话说就是,幂等方法不应该具有副作用。
- 常见的幂等方法:GET,HEAD,PUT,DELETE,OPTIONS
- 常见的非幂等方法:POST
安全的:一个 HTTP 方法是安全的,指的是这是一个对服务器只读操作的方法,不会修改服务器数据。
- 常见的安全方法:GET,HEAD,OPTIONS
- 常见的不安全方法:PUT,DELETE,POST
- 所有安全的方法都是幂等的;有些不安全的方法如 DELETE 是幂等的,有些不安全的方法如 PUT 和 DELETE 则不是
可缓存的:GET、HEAD。
GET 和 POST 的区别
| GET | POST | |
|---|---|---|
| 应用 | 获取服务器的指定数据 | 添加 / 修改服务器的数据 |
| 历史记录 / 书签 | 可保留在浏览器历史记录中,或者收藏为书签 | 不可以 |
| Cacheable | 会被浏览器缓存 | 不会缓存 |
| 幂等 | 幂等,不会改变服务器上的资源 | 非幂等,会对服务器资源进行改变 |
| 后退 / 刷新 | 后退或刷新时,GET 是无害的 | 后退或刷新时,POST 会重新提交表单 |
| 参数位置 | query 中(直接明文暴露在链接中) | query 或 body 中 |
| 参数长度 | 2KB(2048 个字符) | 无限制 |
还有一个常见的说法是「GET 是一次请求;POST 是两次请求,先发 header,服务器返回 100 Continue 后,再发 body」。关于这一点的来源和真实性,请查看知乎这篇文章。
HTTP 状态码
信息响应(100–199)
- 100 Continue:表明到目前为止都很正常,客户端可以继续发送请求或者忽略这个响应
成功响应(200–299)
- 200 OK
- 201 Created:该请求已成功,并因此创建了一个新的资源。这通常是在 POST 请求之后返回的响应
- 204 No Content:该请求已成功处理,但是返回的响应报文不包含实体的主体部分。通常用于只需要从客户端往服务器发送信息,而不需要返回数据时
- 206 Partial Content:服务器已经成功处理了部分 GET 请求,该请求必须包含
Range头信息来指示客户端希望得到的内容范围。通常使用此类响应来实现断点续传,或者将一个大文档分为多个片段然后并行下载
重定向(300–399)
- 301 Moved Permanently:永久性重定向
- 302 Found:临时性重定向。常见应用场景是通过 302 跳转将所有的 HTTP 流量重定向到 HTTPS
- 303 See Other:和 302 有着相同的功能,但是 303 明确要求客户端应该采用 GET 方法获取资源
- 304 Not Modified:如果客户端发送了一个带条件的 GET 请求且该请求已被允许,而文档的内容(自上次访问以来或者根据请求的条件)并没有改变,则服务器应当返回这个状态码。304 响应不包含消息体
- 307 Temporary Redirect:临时重定向。307 与 302 之间的唯一区别在于,当发送重定向请求的时候,307 状态码可以确保请求方法和消息主体不会发生变化;而如果使用 302 响应状态码,一些旧客户端会错误地将请求方法转换为 GET
客户端错误(400–499)
- 400 Bad Request:请求报文中存在语法错误,或者参数有误
- 401 Unauthorized:未认证(没有登录)
- 403 Forbidden:没有权限(登录了但没有权限)
- 404 Not Found
- 405 Method Not Allowed
服务器错误 (500–599)
- 500 Internal Server Error:服务器遇到了不知道如何处理的情况
- 502 Bad Gateway:网关错误,作为网关或代理角色的服务器,从上游服务器(如tomcat、php-fpm)中接收到的响应是无效的
- 503 Service Unavailable:服务器无法处理请求,常见原因是服务器因维护或重载而停机
301、302、307 重定向的原理
返回的 Header 中有一个 Location 字段指向目标 URL,浏览器会重定向到这个 URL。
304 与缓存机制
强制缓存、协商缓存,见从输入一个 URL 到页面加载完成的过程 - HTTP 缓存。
Cookie 与 Session 的区别
二者都是用来跟踪浏览器用户身份的会话方式。
Cookie:
- 存在浏览器里,可以设置过期时间
- 每次访问服务器时,浏览器会自动在 header 中携带 cookie
- 如果浏览器禁用了 cookie,可以使用 URL 重写机制,将信息保存在 URL 里
Session:
- 存在服务端,由服务器维护,一段时间后 session 就失效了
- 本质上,session 还是通过 cookie 实现的。浏览器的 cookie 中只保存一个
sessionId,所有其他信息均保存在服务端,由sessionId标识 - Session 失效,其实是服务器设置了失效时间。如果用户长时间不和服务器交互(比如 30 分钟),那么 session 就会被销毁;交互的话,就会刷新 session
- Session 的实现 - labuladong
HTTP 的长连接与短连接
HTTP/1.0 默认使用的是短连接。也就是说,浏览器每请求一个静态资源,就建立一次连接,任务结束就中断连接。
HTTP/1.1 默认使用的是长连接。长连接是指在一个网页打开期间,所有网络请求都使用同一条已经建立的连接。当没有数据发送时,双方需要发检测包以维持此连接。长连接不会永久保持连接,而是有一个保持时间。实现长连接要客户端和服务端都支持长连接。
长连接的优点:TCP 三次握手时会有 1.5 RTT 的延迟,以及建立连接后慢启动(slow-start)特性,当请求频繁时,建立和关闭 TCP 连接会浪费时间和带宽,而重用一条已有的连接性能更好。
长连接的缺点:长连接会占用服务器的资源。
HTTP/1.0、HTTP/1.1、HTTP/2.0 的变化
HTTP 0.9 - 最初版本
HTTP 的最初版本,请求由单行指令构成,只支持 GET 方法。
HTTP/1.0 - 构建可扩展性
- 在请求中新增了协议版本信息
- 引入了 HTTP 头的概念
- 在响应中新增了状态码
- 默认使用短连接:浏览器每请求一个静态资源,就建立一次连接,任务结束就中断连接
HTTP/1.1 - 标准化的协议
- 默认支持长连接:在一个网页打开期间,所有网络请求都复用同一条已经建立的连接
- Pros:性能更好,节省频繁建立 TCP 连接、慢启动、关闭连接等的时间,整体耗时更短
- Cons:会占用服务器的资源
- 引入额外的缓存控制机制:如
Entity tag、If-None-Match等更多可供选择的缓存头 - 新增了 24 个错误状态响应码,如 409(Conflict)、410(Gone)
- 引入内容协商,允许通信双方约定语言(
Accept-Language)、编码(Accept-Encoding)等 - 支持响应分块(断点续传)
- 引入管线化(Pipelining):从前发送请求后需等待并收到响应,才能发送下一个请求,现在允许客户端同时并行发送多个请求
- Pros:在收到上一个请求的响应之前就可以发出下一个请求,能够节省请求到达服务器的时间,降低通信延迟
- Cons:服务器要遵循 HTTP/1.1 协议,必须按照客户端发送的请求顺序返回响应,可能发生队头阻塞(HOL blocking)——若上一个请求的响应迟迟没有处理完毕,则后面的响应都会被阻塞
- Host 头,允许不同域名配置在同一个 IP 地址上
长连接、管线化都是为了让请求更短时间内结束。
HTTP/2.0 - 为了更优异的表现
HTTP/2.0 的三大特性:Header 压缩、服务端推送、多路复用。
Header 压缩
HTTP/1.1 每次通信都会携带 Header 信息用于描述资源属性。但 headers 在一系列请求中常常是相似的。HTTP/2.0 中,对于 Header 中相同的数据,不会在每次通信中重新发送,而是采用追加或替换的方式。
具体实现上,HTTP/2.0 在客户端和服务端之间共同维护一个 Header 表,存储之前发送的 key-value 对。Header 表在 HTTP/2.0 的连接期间始终存在。
Header 压缩可以减少每次通信的数据量,提高传输速度。
服务端推送
服务器可以对一个客户端请求发送多个响应。服务器向客户端推送资源无需客户端明确的请求。
服务端根据客户端的请求,提前推送额外的资源给客户端。比如在发送页面 HTML 时主动推送其它 CSS/JS 资源,而不用等到浏览器解析到相应位置,发起请求再响应。
服务端推送可以减轻数据传输的冗余步骤,同时加快页面响应速度,提升用户体验。
多路复用
二进制分帧
HTTP/1.x 使用文本格式传输数据。HTTP/2.0 在将所有传输信息分割为若干个帧,采用二进制格式进行编码。
具体实现上,是在应用层(HTTP)和传输层(TCP)之间增加一个二进制分帧层。每个请求对应一个流,有一个唯一的整数标识符。HTTP/1.x 的报文会被拆分为一个或多个帧,每个帧有序列号,以及自己所述的流的标识符,接收端自行合并。
二进制分帧采用更高效的编码协议,提升了传输效率。同时,二进制分帧也为多路复用提供了基础。
多路复用
HTTP/1.x 有顺序和阻塞约束:
- 顺序:服务端必须按照客户端请求到来的顺序,串行返回数据
- 即使 HTTP/1.1 允许通过同一个连接发起多个请求,也无法真正并行传输
- 阻塞:浏览器会限制每个域名下最多同时发起的 6 个连接,超过该数量的连接会被阻塞,以下是常见的优化方法:
- 使用多个域名(比如 CDN)来提高浏览器的下载速度
- 将多个 JS 文件、CSS 文件等打包成一个文件,将多个小图片合并为雪碧图,减少 HTTP 请求数
HTTP/2.0 引入了多路复用,通过同一个连接发起多个请求,服务端可以并行地传输数据。基于二进制分帧层,HTTP/2.0 可以同时交错发送多个消息中的帧,接收端可以根据帧中的流标识符和顺序标识,重新组装数据。
多路复用使用同一个 TCP 连接并发处理同一域名下的所有请求,可以减少 TCP 建立连接带来的时延。此外多路复用代替了 HTTP/1.x 中的顺序和阻塞机制,实现了真正的并行传输,可以避免 HTTP/1.x 中的队头阻塞问题,极大的提高传输效率。
HTTP 报文格式
请求报文
HTTP 协议以 ASCII 码传输,请求报文由请求行、请求头、和消息主体组成。如果有消息主体,那么请求头之后的空行是必须的,用来表示请求头结束:
<method> <request-URL> <version>
<headers>
<entity-body>
GET 请求报文示例:
GET /books/?sex=man&name=Professional HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.6)
Gecko/20050225 Firefox/1.0.1
Connection: Keep-Alive
对于 POST 请求报文,协议规定数据必须放在消息主体中,数据采用的编码方式由开发者自己决定。服务端根据请求头中的 Content-Type 字段获取消息主体的编码方式,再对主体进行解析。
以下是一些常见的 Content-Type 及其对应的消息主体示例:
-
application/x-www-form-urlencoded:POST http://www.example.com HTTP/1.1 Content-Type: application/x-www-form-urlencoded;charset=utf-8 title=test&name=hello -
multipart/form-data:POST http://www.example.com HTTP/1.1 Content-Type:multipart/form-data; boundary=----<boundary> ------<boundary> Content-Disposition: form-data; name="<name1>" <value1> ------<boundary> Content-Disposition: form-data; name="<name2>" <value2> ------<boundary> Content-Disposition: form-data; name="file"; filename="chrome.png" Content-Type: image/png PNG ... content of chrome.png ... ------<boundary>-- -
application/json:POST http://www.example.com HTTP/1.1 Content-Type: application/json;charset=utf-8 {"title":"test","name":"hello"} -
text/xml
详细内容请见四种常见的 POST 提交数据方式 - Jerry Qu。
响应报文
HTTP 响应报文也由三部分组成:状态行、响应头、消息主体。同样的,消息主体前必须有一个空行,表示请求头结束:
<version> <status-code> <reason-phrase>
<headers>
<message-body>
响应报文示例:
HTTP/1.1 200 OK
Date: Mon, 27 Jul 2009 12:28:53 GMT
Server: Apache/2.2.14 (Win32)
Last-Modified: Wed, 22 Jul 2009 19:15:56 GMT
Content-Length: 88
Content-Type: text/html
Connection: Closed
<html><body>
<h1>Hello, World!</h1>
</body></html>
HTTP 报文语法规则
根据 HTTP/1.1 RFC,一个 HTTP 请求报文或响应报文(HTTP-message)符合以下语法:
HTTP-message = Request | Response ; HTTP/1.1 messages
一个 HTTP-message(HTTP 报文)包含 0 个或若干个 message-headers(消息头),可能有一个 message-body(消息主体):
generic-message = start-line
*(message-header CRLF)
CRLF
[ message-body ]
一个 message-body (消息主体) 一定包含一个 entity-body(实体主体),通常情况下消息主体等于实体主体,实体主体也可能经过传输编码机制(Transfer Coding)处理,在通信时按某种编码方式传输:
message-body = entity-body
| <entity-body encoded as per Transfer-Encoding>
从最后一条规则也可以看出,当实体主体经过传输编码后,会分为一组实体主体(<...> 表示列表)。因此,传输编码机制只能作用于分块传输编码中。
HTTP 分块传输编码
在 HTTP 通信过程中,请求的编码实体资源尚未全部传输完成之前,浏览器无法显示请求页面。在传输大容量数据时,通过把数据分割成多块,能够让浏览器逐步显示页面。这种把实体主体分块的功能称为分块传输编码(Chunked Transfer Coding)。
分块传输编码会将实体主体分成多个部分(块),每一块都会用十六进制来标记块的大小,而实体主体的最后一块会使用 0(CR+LF) 来标记。
使用分块传输编码的实体主体会由接收的客户端负责解码,恢复到编码前的实体主体。
注意区分“消息主体”和“实体主体”。《图解 HTTP》将也消息主体称为“报文主体”。
🗂 技术面试题汇总
参考资料
- 版权声明:本文采用知识共享 3.0 许可证 (保持署名-自由转载-非商用-非衍生)
- 发表于 2020-08-22,更新于 2021-04-06